

- The step-by-step approach of Chain-of-Thought (CoT) prompts improves the coherence of responses in complex tasks by systematically breaking down the problem into manageable parts.
- Forced recursion enhances the performance of CoT reasoning by ensuring each step is thoroughly validated before proceeding, though it may introduce significant computational overhead.
- Engaging Kahneman’s System 2 thinking in AI models mirrors human problem-solving processes by emphasizing deliberate and analytical thinking.
- Prompt engineering is crucial in guiding AI models to produce desired outputs by carefully designing prompts that direct the model’s reasoning process effectively.
Table of Contents: (Click any link below to navigate to that section.)
- Why do chain-of-thought (CoT) prompts outperform standard prompts? Are Kahneman’s system 1 and system 2 thinking modes relevant here?
- Does forced recursion of chain-of-thought reasoning yield even better responses, and are there other prompting techniques that produce superior responses?
- Provide 3 examples of queries for which the forced recursion of CoT is recommended.
- Create a 10-item quiz on the entire thread above.
- Provide 15 discussion questions relevant to the content above.


Why do chain-of-thought (CoT) prompts outperform standard prompts? Are Kahneman’s system 1 and system 2 thinking modes relevant here?
Chain-of-Thought (CoT) Prompts vs. Standard Prompts
Chain-of-Thought (CoT) prompts are a technique used in artificial intelligence and natural language processing to enhance the performance of models by encouraging them to think through problems step-by-step, similar to human reasoning. This approach involves breaking down the problem-solving process into a sequence of smaller, more manageable steps, which can help in understanding and solving complex tasks.
Reasons for CoT Prompt Effectiveness
- Decomposing Complexity: CoT prompts help decompose complex problems into simpler sub-tasks. This breakdown makes it easier for the model to handle each part of the problem individually, leading to more accurate and reliable solutions.
- Enhanced Understanding: By guiding the model through a series of logical steps, CoT prompts improve the model’s understanding of the task. This step-by-step approach mimics how humans often solve problems, leading to more coherent and contextually appropriate responses.
- Error Reduction: Standard prompts might lead to errors because they require the model to generate a complete response in one go. CoT prompts, by encouraging step-by-step reasoning, reduce the likelihood of significant errors and help in maintaining consistency throughout the response.
- Memory and Attention: CoT prompts can better leverage the model’s memory and attention mechanisms. Each step in the chain-of-thought process can focus attention on specific parts of the input, improving the overall processing of information.
Relevance of Kahneman’s System 1 and System 2 Thinking Modes
Daniel Kahneman’s theory of System 1 and System 2 thinking provides a useful framework to understand why CoT prompts are effective.
- System 1 is fast, automatic, and often subconscious. It handles routine tasks and quick judgments based on intuition.
- System 2 is slow, deliberate, and conscious. It is used for more complex reasoning and problem-solving tasks that require careful thought.
Application to CoT Prompts
- Engaging System 2: CoT prompts effectively engage a model’s System 2-like capabilities by promoting deliberate, step-by-step reasoning. This mimics how humans engage in detailed problem-solving, ensuring a thorough exploration of the task at hand.
- Balancing Intuition and Deliberation: While standard prompts might rely more on System 1-like quick, intuitive responses, CoT prompts encourage a balance between intuition (System 1) and deliberate reasoning (System 2). This balance helps in producing more accurate and thoughtful outputs.
- Error Checking and Correction: The step-by-step nature of CoT prompts allows for continuous error checking and correction, similar to how System 2 monitors and adjusts the outputs of System 1. This iterative process helps in refining the response and minimizing mistakes.
Conclusion
Chain-of-thought prompts outperform standard prompts primarily because they align more closely with how humans solve complex problems—by breaking them down into smaller steps, enhancing understanding, and reducing errors. Kahneman’s System 1 and System 2 thinking modes are relevant as they illustrate the benefits of deliberate, step-by-step reasoning promoted by CoT prompts, leading to improved performance in complex tasks.
Chain-of-Thought (CoT) Prompts
Chain-of-thought (CoT) prompts outperform standard prompts because they encourage the model to break down a problem into intermediate steps, mimicking the process of step-by-step reasoning that humans often undertake. This approach is particularly effective for complex tasks that require multi-step reasoning or problem-solving.
Relevance of Kahneman’s System 1 and System 2 Thinking Modes
The concepts of system 1 and system 2 thinking, proposed by Daniel Kahneman, are relevant to understanding the effectiveness of CoT prompts.
System 1 thinking is fast, automatic, and intuitive. It is the mode of thinking that we rely on for most routine tasks and decision-making. However, system 1 thinking can sometimes lead to biases and errors, especially when dealing with complex or unfamiliar problems.
System 2 thinking, on the other hand, is slower, more deliberate, and effortful. It is the mode of thinking that we engage when we consciously reason through a problem or perform a complex task. System 2 thinking is more reliable but also more cognitively demanding.
Standard prompts often rely heavily on system 1 thinking, as they do not explicitly guide the model to break down the problem into steps. As a result, the model may sometimes produce incorrect or suboptimal responses, especially for complex tasks that require multi-step reasoning.
CoT prompts, however, encourage the model to engage in system 2 thinking. By prompting the model to explicitly lay out the intermediate steps of its reasoning, CoT prompts force the model to engage in more deliberate and effortful thinking, which can lead to better performance on complex tasks.
In essence, CoT prompts help to overcome the limitations of system 1 thinking by encouraging the model to engage in the more reliable, albeit more cognitively demanding, system 2 thinking mode.
Does forced recursion of chain-of-thought reasoning yield even better responses, and are there other prompting techniques that produce superior responses?
Forced Recursion of Chain-of-Thought Reasoning
Forced recursion in chain-of-thought (CoT) reasoning involves iteratively applying the CoT process to refine responses further. This technique can yield better results by:
- Deepening Understanding: Recursively breaking down each step into smaller sub-steps can lead to a more profound understanding of complex tasks.
- Enhancing Accuracy: Iterative refinement helps in identifying and correcting errors, improving the overall accuracy of the response.
- Improving Coherence: By revisiting and refining each step, the final response is more coherent and logically consistent.
Other Effective Prompting Techniques
- Few-Shot Learning:
- Description: Providing the model with a few examples (shots) of the desired output format before asking it to generate a response.
- Benefits: Improves the model’s ability to generalize from examples, leading to more accurate and contextually appropriate responses.
- Zero-Shot Learning:
- Description: Directly asking the model to generate a response without any examples.
- Benefits: Tests the model’s inherent ability to understand and generate responses based on its training, useful for evaluating the model’s baseline performance.
- Prompt Engineering:
- Description: Crafting prompts with specific instructions, constraints, or context to guide the model’s response.
- Benefits: Directly influences the model’s output, ensuring it adheres to desired formats or focuses on particular aspects of the task.
- Self-Consistency:
- Description: Generating multiple responses to the same prompt and selecting the most consistent or frequent answer.
- Benefits: Reduces variance in responses, leading to more reliable and robust outputs.
- Interactive Prompting:
- Description: Engaging in a back-and-forth interaction with the model, refining the prompt based on interim responses.
- Benefits: Allows for dynamic adjustment and clarification, improving the final output’s relevance and accuracy.
- Reinforcement Learning from Human Feedback (RLHF):
- Description: Using human feedback to iteratively improve the model’s responses through reinforcement learning techniques.
- Benefits: Aligns the model’s outputs with human preferences and values, leading to more satisfactory responses.
Comparison and Context
- Forced Recursion in CoT: Especially useful for highly complex tasks requiring deep, iterative reasoning. It leverages the model’s ability to decompose and refine each step iteratively, leading to detailed and accurate responses.
- Few-Shot and Zero-Shot Learning: Effective for tasks where examples can provide clear guidance or where the model needs to leverage its pre-existing knowledge without specific examples.
- Prompt Engineering: Best for tasks requiring specific formats or constraints. It allows for direct control over the model’s focus and output style.
- Self-Consistency: Useful when reliability and consistency of responses are paramount, particularly in tasks where variance in responses is undesirable.
- Interactive Prompting: Ideal for complex, nuanced tasks requiring clarification and refinement. It benefits from the dynamic interaction between the user and the model.
- RLHF: Superior for aligning the model’s outputs with human values and expectations, making it particularly valuable for applications requiring high levels of user satisfaction and ethical considerations.
Conclusion
While forced recursion in CoT reasoning can yield superior responses for complex tasks by enhancing accuracy and coherence through iterative refinement, other prompting techniques like few-shot learning, prompt engineering, and RLHF offer valuable alternatives tailored to different contexts and requirements. The choice of technique depends on the specific task, desired outcome, and available resources for interaction and feedback.
Forced Recursion of Chain-of-Thought Reasoning
There is some evidence that forcing the model to perform multiple iterations of chain-of-thought reasoning can further improve performance on complex tasks. This approach, sometimes referred to as “recursive chain-of-thought prompting,” involves prompting the model to not only lay out its initial chain of reasoning but also to critique and refine that reasoning in subsequent steps.
By repeatedly revisiting and refining its thought process, the model is encouraged to engage in even deeper and more deliberate reasoning, potentially catching and correcting errors or oversights in its initial reasoning. This recursive approach can be particularly beneficial for tasks that require significant logical complexity or domain-specific knowledge.
However, it’s important to note that recursive chain-of-thought prompting can also increase the computational cost and latency of the model’s responses, as it involves multiple rounds of reasoning. There may be a trade-off between performance and computational efficiency that needs to be considered.
Other Prompting Techniques
While chain-of-thought prompting has proven to be a powerful technique, there are several other prompting strategies that can also yield superior responses in certain contexts:
- Few-shot prompting: Providing the model with a small number of examples of the desired task or output can help guide the model’s reasoning and improve performance, especially for tasks that are difficult to specify with instructions alone.
- Prompt tuning: Fine-tuning the language model on a small dataset of prompts and desired outputs can significantly improve its performance on specific tasks or domains.
- Prompt ensembling: Combining the outputs of multiple prompts or models can lead to more robust and accurate responses, as different prompts or models may capture different aspects of the task or problem.
- Prompt augmentation: Augmenting the prompt with additional context or information, such as relevant background knowledge or domain-specific facts, can help the model better understand and reason about the task at hand.
The effectiveness of these prompting techniques can vary depending on the specific task, domain, and characteristics of the language model being used. In many cases, a combination of different prompting strategies may yield the best results.
Provide 3 examples of queries for which the forced recursion of CoT is recommended.
Examples of Queries for Forced Recursion of Chain-of-Thought (CoT) Reasoning
1. Complex Mathematical Problem
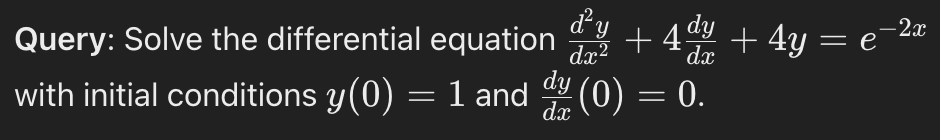
Why Forced Recursion is Recommended: This problem involves multiple steps, including identifying the type of differential equation, finding the homogeneous solution, finding a particular solution, and applying initial conditions. Recursively breaking down each step ensures accuracy and completeness.
Steps:
- Identify the differential equation type.
- Solve the homogeneous part of the equation.
- Find a particular solution to the non-homogeneous part.
- Apply the initial conditions to find the specific solution.
2. Legal Analysis of a Complex Case
Query: Analyze the legal implications of a company’s decision to terminate an employee who has been whistleblowing on corporate malpractices, considering U.S. federal and state laws.
Why Forced Recursion is Recommended: This query requires understanding various legal aspects, including employment law, whistleblower protections, and potential repercussions for both the company and the employee. Recursively breaking down the analysis into legal frameworks, case studies, and possible outcomes provides a thorough examination.
Steps:
- Review federal whistleblower protection laws.
- Review relevant state laws.
- Analyze past legal precedents and case studies.
- Consider the specific details of the current case.
- Synthesize findings to provide a comprehensive legal opinion.
3. Detailed Historical Analysis
Query: Provide a comprehensive analysis of the economic, social, and political factors that led to the fall of the Western Roman Empire.
Why Forced Recursion is Recommended: This query involves multiple interrelated factors spanning several centuries. Recursively breaking down the economic, social, and political aspects allows for a detailed and nuanced understanding of the causes and effects leading to the fall.
Steps:
- Analyze the economic factors (e.g., inflation, trade decline).
- Examine social changes (e.g., population decline, migration).
- Investigate political issues (e.g., leadership, military challenges).
- Explore the interactions between these factors.
- Summarize the overarching reasons for the empire’s decline.
Conclusion
Forced recursion of CoT reasoning is highly beneficial for complex queries requiring in-depth analysis and multiple interrelated steps. By recursively breaking down each part of the problem, it ensures a comprehensive and accurate response, making it ideal for solving complex mathematical problems, conducting legal analyses, and performing detailed historical studies.
Here are three examples of queries for which forced recursion of chain-of-thought (CoT) reasoning is recommended:
- Complex Multi-Step Math Word Problems
Example: “There are three times as many dogs as cats in a pet shelter. If there are 12 more dogs than cats, and there are 24 cats in total, how many dogs are in the pet shelter?”
For multi-step math word problems like this, forced recursion of CoT can help the model break down the problem into smaller steps, catch and correct any mistakes in its initial reasoning, and arrive at the correct solution.
- Logical Reasoning and Puzzle-Solving Tasks
Example: “Using only four 4’s and basic mathematical operations, how can you represent all the numbers from 0 to 20?”
Logical reasoning and puzzle-solving tasks often require finding creative solutions through a series of logical steps. Forced recursion of CoT can help the model explore different lines of reasoning, backtrack when necessary, and potentially uncover novel solutions.
- Analyzing Complex Scenarios or Case Studies
Example: “Analyze the potential ethical implications of using AI-generated deepfake technology in news reporting and journalism.”
When analyzing complex scenarios or case studies that involve multiple factors, forced recursion of CoT can help the model consider different perspectives, identify potential issues or concerns, and develop a more nuanced and well-reasoned analysis.
In all these examples, the recursive application of CoT reasoning can encourage the model to engage in deeper and more deliberate thinking, potentially leading to better performance on tasks that require significant logical complexity, creativity, or nuanced analysis.
Create a 10-item quiz on the entire thread above.
Quiz
- What is the primary reason Chain-of-Thought (CoT) prompts outperform standard prompts?
- How do Chain-of-Thought prompts reduce the likelihood of significant errors in responses?
- Which of Daniel Kahneman’s thinking modes is engaged by CoT prompts, System 1 or System 2?
- Name one benefit of forced recursion in Chain-of-Thought reasoning.
- What prompting technique involves providing a model with a few examples of the desired output format before generating a response?
- Which prompting technique is particularly useful for aligning a model’s outputs with human values and expectations?
- What is the main difference between few-shot learning and zero-shot learning?
- In the context of CoT reasoning, why is iterative refinement important for complex tasks?
- What type of query would benefit from forced recursion of CoT due to involving multiple legal aspects?
- Explain why forced recursion is recommended for detailed historical analysis.
Answers
- CoT prompts outperform standard prompts because they break down complex problems into smaller, manageable steps, enhancing understanding and reducing errors.
- By encouraging step-by-step reasoning, CoT prompts reduce the likelihood of significant errors and help maintain consistency throughout the response.
- System 2 thinking mode is engaged by CoT prompts.
- One benefit of forced recursion in CoT reasoning is enhancing accuracy through iterative refinement.
- The prompting technique that involves providing a model with a few examples is called few-shot learning.
- Reinforcement Learning from Human Feedback (RLHF) is particularly useful for aligning a model’s outputs with human values and expectations.
- The main difference is that few-shot learning provides examples before generating a response, while zero-shot learning asks the model to generate a response without any examples.
- Iterative refinement is important for complex tasks as it helps in identifying and correcting errors, ensuring a thorough and accurate solution.
- A query analyzing the legal implications of a company’s decision to terminate an employee who has been whistleblowing on corporate malpractices would benefit from forced recursion of CoT.
- Forced recursion is recommended for detailed historical analysis because it allows for a nuanced understanding of multiple interrelated factors spanning several centuries.
Here’s a 10-item quiz on the thread above:
- What is the purpose of chain-of-thought (CoT) prompts?
- What are the two thinking modes proposed by Daniel Kahneman?
- Which thinking mode is faster and more intuitive, but can lead to biases?
- Which thinking mode is slower and more deliberate, but more reliable?
- How do CoT prompts help overcome the limitations of the faster thinking mode?
- What is “recursive chain-of-thought prompting”?
- What is a potential trade-off of recursive chain-of-thought prompting?
- Name one other prompting technique mentioned in the thread.
- For what type of task is forced recursion of CoT recommended?
- In the example given, how many dogs are in the pet shelter?
Answers:
- To encourage the model to break down a problem into intermediate steps, mimicking step-by-step reasoning.
- System 1 and System 2 thinking.
- System 1 thinking.
- System 2 thinking.
- By encouraging the model to engage in the more reliable System 2 thinking mode.
- Prompting the model to repeatedly revisit and refine its thought process.
- Increased computational cost and latency.
- Few-shot prompting, prompt tuning, prompt ensembling, or prompt augmentation.
- Complex multi-step math word problems, logical reasoning and puzzle-solving tasks, or analyzing complex scenarios or case studies.
- 36 dogs.
Provide 15 discussion questions relevant to the content above.
Discussion Questions
- How does the step-by-step approach of Chain-of-Thought (CoT) prompts improve the coherence of responses in complex tasks?
- In what ways does forced recursion enhance the performance of CoT reasoning, and what are some potential drawbacks?
- How does engaging Kahneman’s System 2 thinking in AI models compare to human problem-solving processes?
- What are some examples of tasks where few-shot learning might outperform CoT prompts, and why?
- How does Reinforcement Learning from Human Feedback (RLHF) contribute to the ethical alignment of AI models?
- What challenges might arise when using zero-shot learning for highly specialized tasks?
- Discuss the importance of prompt engineering in guiding AI models to produce desired outputs.
- How can self-consistency techniques help in reducing the variance in AI model responses?
- What are the key differences between interactive prompting and other prompting techniques in refining AI responses?
- In what scenarios would iterative refinement be critical for achieving accurate AI outputs, and how can it be implemented effectively?
- Why is forced recursion particularly recommended for legal analysis tasks involving multiple legal frameworks and precedents?
- How can the use of CoT prompts and forced recursion aid in historical research and analysis?
- What role does decomposing complex problems into smaller steps play in improving AI model performance?
- Discuss the potential benefits and limitations of using forced recursion in mathematical problem-solving.
- How does breaking down economic, social, and political factors in historical analysis help achieve a comprehensive understanding of events like the fall of the Western Roman Empire?
Here are 15 discussion questions relevant to the content on chain-of-thought prompting and Kahneman’s thinking modes:
- Can you think of any other examples where CoT prompting could be particularly useful besides the ones mentioned?
- How might the effectiveness of CoT prompting vary across different types of language models or model architectures?
- Are there any potential downsides or limitations to CoT prompting that were not discussed?
- How might the concepts of System 1 and System 2 thinking apply to human-AI interaction and the design of user interfaces?
- Can you think of any real-world examples where over-reliance on System 1 thinking has led to significant errors or consequences?
- Aside from CoT prompting, are there any other techniques or strategies that could help encourage System 2 thinking in AI systems?
- How might the balance between System 1 and System 2 thinking shift as AI systems become more advanced and capable?
- Could there be situations where relying too heavily on System 2 thinking could be detrimental or inefficient?
- How might the concepts of System 1 and System 2 thinking inform the design of educational curricula or teaching methodologies?
- In what ways might the distinction between System 1 and System 2 thinking be an oversimplification or fail to capture the full complexity of human cognition?
- How might the use of CoT prompting or other techniques that encourage System 2 thinking affect the interpretability or transparency of AI systems?
- Could there be ethical considerations or potential biases associated with the use of CoT prompting or other techniques that alter an AI system’s reasoning process?
- How might the use of CoT prompting or similar techniques evolve as AI systems become more multimodal and capable of processing different types of data (e.g., images, videos, audio)?
- Are there any potential risks or concerns associated with AI systems becoming too reliant on System 2 thinking and failing to incorporate the intuitive and efficient aspects of System 1 thinking?
- How might the concepts of System 1 and System 2 thinking be relevant to other fields or areas of study beyond AI and cognitive science?
Table of Contents: (Click any link below to navigate to that section.)
- Why do chain-of-thought (CoT) prompts outperform standard prompts? Are Kahneman’s system 1 and system 2 thinking modes relevant here?
- Does forced recursion of chain-of-thought reasoning yield even better responses, and are there other prompting techniques that produce superior responses?
- Provide 3 examples of queries for which the forced recursion of CoT is recommended.
- Create a 10-item quiz on the entire thread above.
- Provide 15 discussion questions relevant to the content above.








Leave a comment